新华三集团
互联网与定制化技术部
Agentic AI
重构业务范式
首先,和大家谈谈Agents、AI Agents、Agentic AI这三个词汇背后的关联。Agents是一个最基础的概念,任何能感知环境并为达成目标而行动的实体,都可以称之为Agents。AI Agents在Agents基础上增加了大模型的能力,具备了记忆能力及自主规划/决策能力。而Agentic AI则是AI Agents追求的更高阶形态,更加强调自主性、目标驱动、环境交互与反思学习。
一个典型的AI Agent系统应具备三大模块:感知模块、认知与决策模块、行动模块。
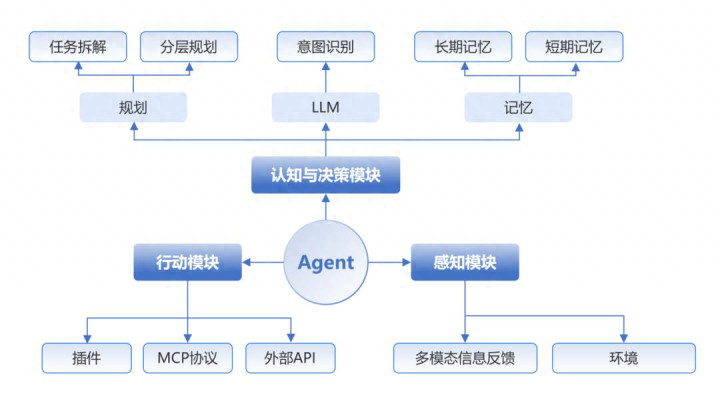
感知模块,关键在于通过NLP、CV、ASR等技术构建环境状态表征。
认知与决策模块,多模态大模型的持续优化是核心。围绕大模型的RAG知识库、向量数据库、元学习等将是重要的能力补充。
行动模块,MCP协议(Anthropic)的诸多限制亟待解决,人机交互/物理交互将延申AI Agents应用领域。
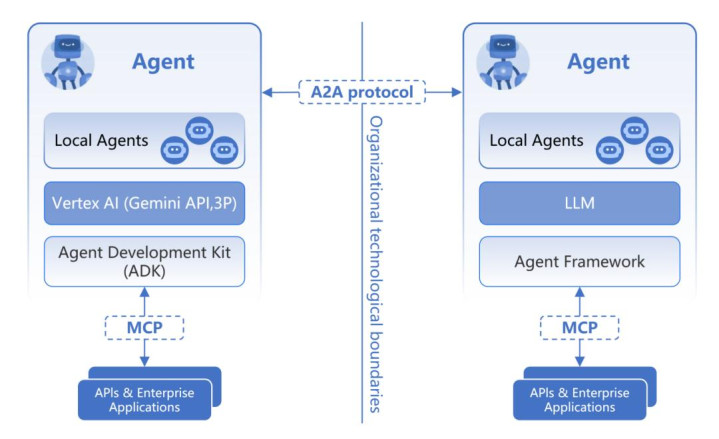
多个AI Agent系统则通过A2A协议(Google)进行交互。在多AI Agent系统内,Agents的发现、认证/授权、状态管理则需要重点关注。如下图所示:
最后则是交互层面的AG-UI,通过轻量化的HTTP实现Agent与前端的双向连接,并同时可以兼容多种Agent开发框架。
到这里,想必大家已经对AI Agent及Agentic AI有了一定的认知,那么接下来我们将重点剖析这套新的业务范式对基础架构将带来怎样的影响。
典型应用架构
从应用编程的纬度来看,此前我们通过Java/Python等对计算机进行编程,之后我们又通过参数调参对神经网络进行编程,而在Agentic AI时代我们则是通过提示词/上下文等对大模型进行编程。此前程序的载体主要是CPU,而在Agentic AI时代程序的载体主要是GPU。
从应用架构的纬度来看,Agentic AI与当下云原生/微服务模式存在巨大差异。此前AWS发布了Bedrock AgentCore解决方案,其包含了7大核心组件:AgentCore Runtime、AgentCore Memory、AgentCore Identity…国内阿里云同样推出了较完整的AI原生应用框架组件。
参考以上两家公司的解决方案,我们可以抽象出一个典型的Agentic AI应用的典型架构:
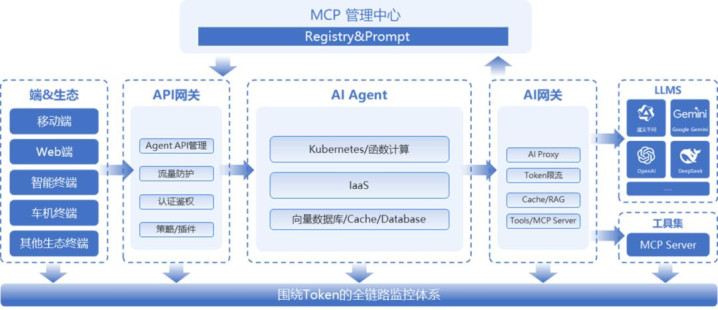
这个应用架构的核心是AI Agent,AI Agent可以基于不同的开发框架进行构建,且需要部署于计算实例中,与此同时AI Agent需要与多个组件进行交互。
用户需求传递至该应用时需要经过安全管控及授权的组件,我们称之为API网关,该网关同时兼具“多Agents API管理”的功能,以便于用户需求调度至不同AI Agent。
AI Agent需要进行“决策”,即对接LLMs,不同大模型平台的接口协议不同,因此需要中间层进行屏蔽。AI Agent还需要进行“执行”,即对接MCP Servers,这里同样需要一个中间层进行协议转换。我们将这个中间层称为“AI网关”。此外,由于MCP Server众多,还需要有一个MCP管理中心来管理MCP Server的注册与发现。
最后则是监控组件,需要建立围绕Token的全链路监控体系,以便于应用开发者提高效率与节省成本。
对基础架构/基础设施的影响
(计算)
Agentic AI将把AI推理推向新的高潮,而推理加速将变得至关重要。我们常提起两个指标:TTFT(Time to First Token)、TPOT(Time Per Output Token),前者决定了我们模型推理的流畅度,后者决定了模型在Decode阶段的关键性能。接下来我们将站在系统架构维度来谈一下如何提升这两个指标。
随着AI Agents复杂度的提升,如何将Prompt、RAG、Context等多种信息高效准确地传递给LLM,即上下文工程,变得至关重要。它不仅是信息的组织与压缩,更直接关系到显存带宽利用效率和推理延迟的优化。通过层次化Context管理、增量更新和注意力窗口的智能裁剪,可以在有限序列长度内最大化有效信息密度,从而提升KV缓存命中率并降低访存开销。KV缓存的命中率极大影响Agent运行效率,优化策略如前缀缓存、分块预填充及滑动窗口注意力配合混合管理器,能有效控制长序列下的缓存增长,确保高吞吐与低延迟。
另一方面,在多Agents系统中,高强度任务调度对CPU高核数提出了需求,系统面临异构并行挑战:GPU负责大模型推理,而CPU需高效处理任务分解、负载均衡与通信同步,存储子系统则要应对多级缓存一致性与高速数据交换的压力。这些技术点相互关联,共同构成了提升复杂智能体系统性能的关键路径。
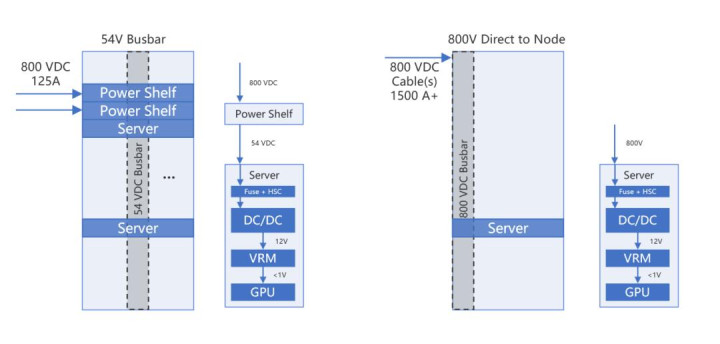
与此同时,随着单个AI机柜功率向兆瓦级迈进,供电架构已成为制约算力密度的关键瓶颈。传统供电体系在空间侵占、铜材消耗和转换效率等方面已触及物理与经济极限。生成式AI的狂飙突进,正倒逼数据中心从“低电压交流多级转换”向“高压直流原生直通”的范式转移。2025 OCP大会上,英伟达提出800VDC架构,通过将配电电压提升至800V高压直流,大幅降低传输电流,从根本上破解高电流带来的空间占用、线缆成本和能量损耗难题,为高密度算力柜释放宝贵空间,并实现端到端能效的量子跃迁。

由此,我们看到的是:一个单Agent或者多Agents系统的运行,不仅需要GPU/CPU/存储系统的同步优化与提升,更依赖于与之匹配的高效供电架构。这里我们设想出一个合理的计算与内存协同架构:
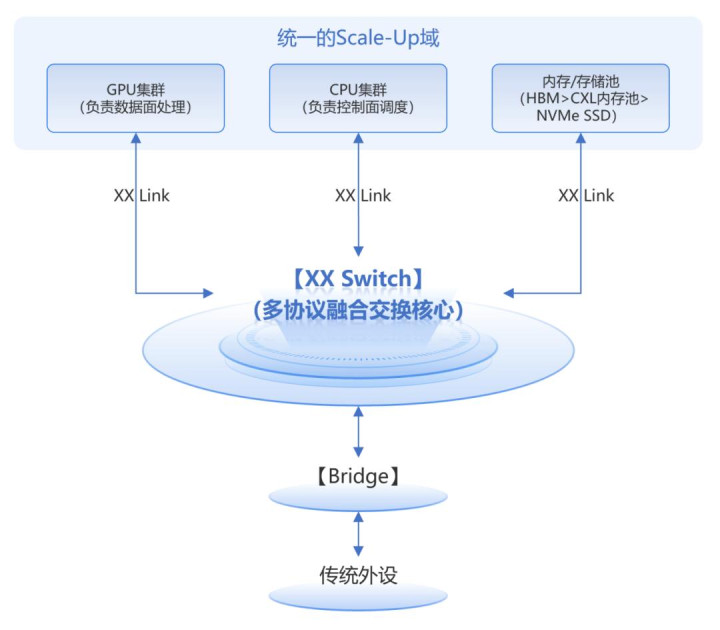
GPU/CPU/存储处于同一个Scale-up域内,基于Agents运行需要独立进行扩展,三者通过XX Switch进行互联。业界生态来看:NVLink与UB都是相同的理念,同时也有一些开源组织在推进相关协议标准,例如:CXL与UALink。至于CXL,其基于速率迭代缓慢PCIe物理层,CXL核心价值在于实现AI计算环境下的一致性内存访问,其优势在于兼容性强,可平滑兼容现有数据中心架构。但太过臃肿,且协议栈较为复杂,在追求极致性能的AI训练前端网络中面临延迟与效率的挑战。CXL的未来定位更侧重于内存资源的池化与共享,是构建统一内存架构的关键技术,但未必适用于GPU间高性能计算场景。我们寄希望于后续XXLink(如UALink、NVLink Fusion)能够进一步完善其生态。
接下来我们看下基础设施计算领域核心部件生态的XXLink适配动向与战略布局:
GPU:Agentic AI体系的核心,互联能力成为算力基石
GPU已从单一的计算加速器演变为高速计算网络中的核心节点,其互联能力直接决定了集群的算力效率与扩展上限。以NVIDIA为例,其通过NVLink/NVSwitch技术,在GPU互联领域建立了难以逾越的垂直生态壁垒。自2020年推出的Ampere架构,首次在单节点内通过NVSwitch创造了全互联拓扑,到如今最新的Blackwell架构,将NVLink域扩展至GPU+CPU已成为主流方案,再到2026年即将推出的Rubin架构,通过新一代NVswitch及NVLink6.0技术进一步突破带宽瓶颈,提升柜内GPU部署密度。对于其他新入局的AI芯片厂商而言,我们认为支持UALink或类似高性能开放XXLink互连协议,是切入主流AI数据中心市场的最佳策略。
GPU芯片内部,Chiplet架构越来越成为主流,可以有效提升晶圆良率,从而降低整体制造成本并实现灵活组合。但目前每家芯片厂商都在使用独有的die间互连协议、通信标准、管理接口,A厂商CPU Chiplet无法与B厂商I/O Chiplet协同工作,芯片内每一对Chiplet组合都进行单独且复杂的底层适配,并未达到Chiplet即插即用的本意,互操作性成为Chiplet开放生态最核心的障碍。2025 OCP大会上,ARM推出了基础小芯片系统架构 FCSA,通过定义一套完整的协议栈和接口标准,确保来自不同供应商、不同工艺节点、不同功能的Chiplet能够在一个封装内可靠、高效、安全地协同工作,最大化提升芯片单位的密度,并降低功耗和成本。如果FCSA生态能普及,未来将看到一个更加繁荣和多样化的Chiplet市场,这必将加速为复杂AI Agents任务而深度优化的、高度解耦的开放计算架构的诞生。
由此可见:现代GPU的互联能力已深度融入其内外架构设计,外部通过XXLink接入到Switch实现节点内乃至集群内所有GPU的高带宽低延迟连接、内部通过超高带宽的硅中介层实现计算die间接近零延迟通信。Agentic AI时代下的GPU正以互联能力为基石,逐步成为AI Agents算力的核心。
CPU:角色重塑,从中心控制器到对等协调者
Agentic AI体系下,CPU不再主导数据面计算,CPU的角色正由传统的计算核心转变为负责任务调度、资源管理与协同计算的对等协调者。未来CPU将更专注于控制面逻辑,例如Agent工作流编排、资源调度、安全隔离。在数据面,则需通过高速互连网络直接高效地访问GPU HBM及远端池化内存,这对互连协议的缓存一致性与延迟性能提出了极高要求。下一代数据中心CPU已在此方向展开布局,通过集成高速互联IP(XXLink die),以保证其在AI计算网络中的高效互联能力。在未来架构演进上,CPU原生支持高性能开放XXLink互连协议(如UALink/NVLink Fusion)会是一个必选项,性能上可以突破PCIe链路瓶颈,使得CPU-GPU在同一个低延迟、高带宽的“Scale-Up域”内对等协作。
CPU架构的转变要求芯片厂商必须进行全栈革新:首先芯片的对外扩展成为设计重心,随着信号速率的大幅提升,将从传统铜互连转向光互连,以突破带宽和能效瓶颈。其次传统CPU集成大面积IMC用于直接控制本地的DDR,内存池的存在可以减少IMC占用面积,将宝贵的芯片资源分配给更强大更密集的I/O Die,以支持对外的XXLink高性能开放互连协议。
这一切革新汇聚于系统架构层面,其核心是从传统的以CPU为中心的内存一致性模型,过渡到一个全局性的、缓存一致性的互联网络。单节点本地内存的扩展、核存比将变得不再重要,CPU计算单元能像访问本地内存资源一样高效共享池化内存,最终实现CPU从“中心控制器”到“对等协调者”的角色转变,为复杂多Agent系统提供近乎无限的横向扩展能力和资源弹性。

存储:从单一GPU/CPU附属资源到全局可池化资产
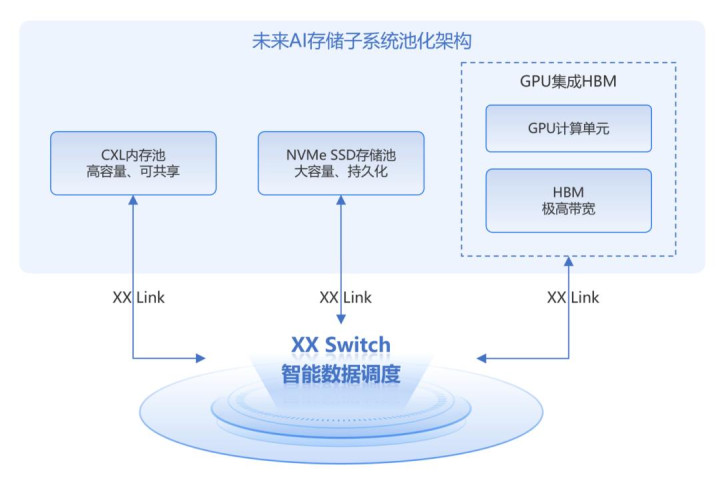
HBM已成为满足GPU算力需求的关键,HBM容量随工艺制程的提升而持续增长是必然趋势,同时受限于GPU芯片尺寸,单GPU集成的HBM容量也只能有限增长。内存池化(Memory Pooling)将有助于高性能显存从“固定依附于特定处理器”向“全局可池化、可共享的资源”演进。借助XXLink技术结合,一是使GPU能够透明访问共享的大规模HBM显存资源;二是可以访问全局的池化内存,极大地扩展了有效可寻址空间,缓解了KV Cache压力。
当前XXLink技术专注于点对点连接,优化计算单元之间的数据交换。现阶段,在内存池领域,CXL仍具备“内存容量扩展、协议级缓存一致性”等核心优势。因此将CXL和XXLink整合到统一的数据中心架构(即CXL over XXLink)中,可充分发挥两者的互补优势,优化整体系统性能。未来,我们可以设想,内存池将直接通过XXLink Switch接入Scale-up域。同样在NVMe SSD领域,当前通过存储扩展卡/CXL Switch可实现永久存储池化,将来同样可以支持XXLink协议。这就需要整个存储部件生态进行一场彻底的变革。
可以看到:未来存储子系统将呈现多层化结构,根据介质速率将形成HBM(最快)>池化内存(大容量)> NVMe SSD(持久化存储)的多层结构,由特定的硬件加速器及XXLink协议协同管理数据在层级间的流动,确保数据始终处于最适合的计算单元附近。
供电架构:从交流多级转换到800VDC原生直通
随着下一代AI算力机柜功率突破兆瓦级,传统供电架构在空间、铜耗与效率方面遭遇瓶颈。800VDC架构通过电压提升大幅降低传输电流,从根本上解决高电流难题。具体实施存在两条路径:54V总线架构则更为稳健,在机柜内先行降压,兼容现有生态;800V总线架构采用“高压直降”技术,通过高变比LLC谐振转换器一步到位将电力降至芯片所需电压,效率与密度最优。我们认为800VDC原生总线架构将是下一代AI算力机柜电力供给明确的技术趋势方向。
特性维度
54V总线架构
800V原生总线架构
系统效率
相对较低:存在机柜级和服务器级两级转换,能量损耗较大。
极高:省去机柜级转换,供电路径最短,损耗最小。
功率密度
受限:集中降压单元占用空间,且为承载大电流,配电母线粗重,挤占计算资源空间。
极高:配电系统小巧简洁,所有空间最大化用于计算单元,是实现兆瓦级机柜的关键。
技术成熟度
高:服务器可直接沿用成熟的54V电源供应链,部署风险低。
快速成熟中:是明确的技术前沿方向,但服务器电源需重新设计。
总拥有成本
线缆成本高:机柜内大电流需要更粗、更昂贵的铜缆。
线缆成本低:低电流允许使用更细、更经济的线缆。
OCP等组织也在积极推动800VDC机柜、连接器与安全规范的统一,构建从芯片(GaN、SiC)到系统集成的协同生态。供电架构的革新与计算互联相辅相成,共同支撑高密度、高弹性的Agentic AI算力基础。
综上所述,GPU、CPU、存储及供电四大核心组件的技术发展正强力驱动Agentic AI算力架构的革新。我们预计未来将形成“底层以太网物理层承载,上层多逻辑通道并存”的融合互联架构。XXLink Switch将演进为该架构的智能核心,同时依然保留Bridge通道连接到XXSwitch上,保障了新技术迭代过程中的传统外设的平稳过渡。
因此,Agentic AI时代的计算设施终极形态可以有如下构思:通过多柜集成,实现GPU计算、CPU调度、存储资源的完全解耦及动态组合,显著提高资源利用率、部署灵活性及能效优化配比。该架构通过模块化Tray设计:整机柜被划分为多个功能专精的Tray,每个Tray专门承载特定类型的资源池,各自放置在不同的整机柜上,因此外观形态上不需要follow传统的单柜高密Tray盘设计。

通过上述基础设施构想,实现计算、内存、存储及电力资源的完全解耦与协同优化,系统可以根据任务需求,动态地为AI Agents组合不同数量的GPU、内存和存储资源,并配以高效的能源供给,实现真正的资源即服务。
对基础架构/基础设施的影响
(DCN网络)
AI Agents作为一种高级的推理任务,对底层硬件基础设施网络侧提出了不同以往的新挑战。首先大量的并行计算任务如TP和EP,对网络带宽的需求极高,远高于Scale-out网络所能带来的带宽能力。其次,许多agent需要处理超长的上下文文本,并且agent在进行用户多轮对话交互时,需要连续的参考之前的长上下文,KV Cache的规模迅速膨胀,因此对网络的显存容量和端到端时延提出了极致的要求,并且要求网络具有极高的吞吐和高并发的处理能力,以同时处理大量用户请求。在模型层面,Transformer架构由Dense架构正在向MoE架构演进,这种稀疏专家网络通过动态任务分配机制,使模型参数规模突破万亿级的同时保持计算效率。在算力层面,单机算力已触及物理瓶颈,集群化算力整合和调度成为必然选择。
为满足AI agent的网络需求,业界当下聚焦于Scale-Up架构。Scale-Up架构扩展到一定规模时,便形成了所谓的超节点(SuperPod),超节点的优势在于其统一的内存语义和高度集成的架构。由于所有GPU都处于同一个超带宽域(HBD, High Bandwidth Domain),它们之间的通信延迟极低,数据交换效率极高。这使得超节点能够高效处理大规模张量计算和专家并行任务,从而加速大模型的训练和推理过程。
在AI大模型和AI agent持续演进的推动下,数据中心内部的Scale-up(纵向扩展)网络正经历一场深刻的架构变革。这一变革的核心,是从传统的电互联向光互连跃迁,同时从封闭私有协议走向开放标准生态,其背后是对更高带宽、更低延迟、更低功耗以及更强可扩展性的综合追求。
早期的Scale-up系统主要依赖铜缆实现芯片间或服务器间的高速互联。典型的如“Cable Tray”架构,通过密集布线将多个GPU或AI加速器连接到主机或交换结构上。这种方案虽然在小规模部署中具备成本优势和部署便捷性,但随着节点数量增加,铜缆的物理体积、重量、电磁干扰以及信号衰减问题迅速凸显,限制了系统密度和性能扩展。随后出现的“正交架构”(Orthogonal Architecture)通过计算节点与交换节点的正交联接,优化走线路径,减少信号串扰,在一定程度上缓解了布线瓶颈,但本质上仍受限于电互联的物理极限——尤其在112Gbps以上速率,铜缆传输距离急剧缩短,难以支撑未来AI集群对带宽持续增长的需求。
在此背景下,光互连技术成为Scale-up网络演进的必然方向。光互连路线呈现出清晰的三阶段演进路径:从LPO(Linear-drive Pluggable Optics,线性驱动可插拔光模块),到NPO(Near-packaged Optics,近封装光模块),再到CPO(Co-packaged Optics,共封装光模块)。LPO通过简化传统光模块中的DSP(数字信号处理器),降低功耗与延迟,适用于400G/800G主流场景;NPO则将光引擎更靠近交换芯片,缩短电通道长度,提升能效比;而CPO则彻底打破传统“交换芯片+独立光模块”的分离式设计,将光引擎与交换ASIC共封装在同一基板上,大幅减少I/O功耗与物理空间占用。CPO作为终极方案,优点虽然很明显,但是当前生态不够开放解耦,不利于CPO方案的快速实现和落地。相比之下NPO方案生态较好,可以实现方案的快速落地,我们判断在超节点规模越来越大的背景下,NPO方案可能会成为Scale-Up光互连的主流方案。

Scale-Up网络NPO方案
与物理层演进同步发生的是协议层的范式转移。过去,Scale-up网络高度依赖厂商私有协议,如NVIDIA的NVLink和华为的UB(Unified Bus),这些协议在特定硬件生态内实现了极致性能,但形成了“技术孤岛”,限制了异构算力整合与生态开放。随着AI基础设施走向通用化和标准化,行业迫切需要开放、可互操作的高速互联协议。由此,UALINK、ESUN(Ethernet for Scale-Up Networks)等开放标准应运而生。UALINK由多家头部厂商联合推动,支持多芯片互连与内存共享;ESUN则尝试将以太网引入Scale-up场景,专注于L2帧结构和L3网络交换,利用以太网成熟的生态实现“统一网络”愿景——即用同一套以太网基础设施同时承载Scale-up与Scale-out流量。
这一双重演进趋势——物理层从电到光、协议层从封闭到开放——标志着Scale-up网络正从“专用高性能孤岛”向“开放、高效、可持续”的智能互联基础设施转型。它不仅解决了当前AI大模型训练和推理中的通信瓶颈,更为未来训推一体、存算一体、甚至AI Agent自主调度等高级能力奠定了网络基础。可以预见,在开放光互连架构的支撑下,下一代数据中心将实现算力资源的无缝聚合与智能调度,真正迈向“网络即算力”的新阶段。
为支持更大规模的训练和推理需求,数据中心Scale-out网络也正经历从RoCE向新一代协议的范式跃迁。传统RoCE虽已广泛部署,但其负载均衡、乱序重传、拥塞控制复杂等问题,难以满足大规模AI集群的需求。在此背景下,UEC(超以太网联盟)、ETH+(高通量以太网)等新技术通过多项创新重塑AI网络性能边界。UEC通过多路径数据包喷洒、选择性重传、LLR、CBFC等技术,实现百万级节点集群的流量智能调度和拥塞控制。这些技术的突破不仅解决了传统瓶颈,更推动AI网络从"尽力而为"向"智能可靠"的质变。AI Agent深度集成将赋予网络实时自优化能力。开放标准的普及加速了AI网络的普及,其生态兼容性更易形成规模化效应。随着UEC规范和ETH+产业化落地,AI网络正迈向高效、智能、开放的新阶段,为下一代AI基础设施提供关键支撑,推动算力网络实现从"传输管道"到"智能中枢"的跃迁。
随着AI大模型训练规模突破万亿参数、超节点规模向千卡级迈进,高性能网络(HPN)正面临从“分离架构”向“统一生态”的范式转变。这一变革的核心在于DCN网络、Scale-up(纵向扩展)与Scale-out(横向扩展)网络的深度耦合,其背后是算力需求激增、通信模式升级和协议标准演进的多重驱动。
首先,超节点的扩张催生了Scale-out与DCN的融合。传统数据中心长期将Scale-out网络与DCN(数据中心网络)视为独立层级:前者负责万卡级集群的弹性扩展,后者承担传统云计算资源的互联。当超节点规模从百卡级跃升至千卡级时,大部分的流量均可在超节点Scale-up网络域内完成,相应的用于联接超节点之间的Scale-out网络流量会大幅减少。随着DCN网络带宽的稳步增长,以及DCN内应用全域支持RDMA,Scale-out网络和DCN网络融合成为可能。超节点作为DCN接入的一个层级,将成为DCN网络演进的新的变化。
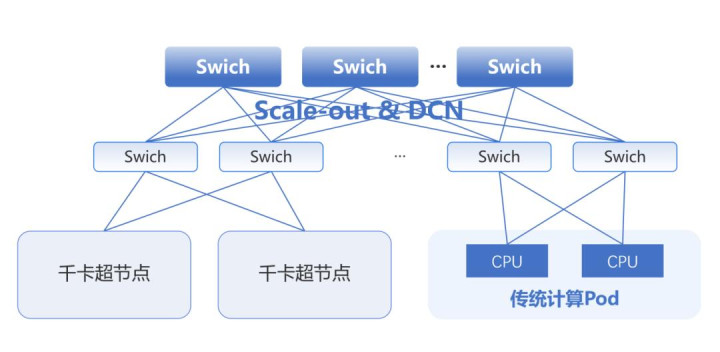
Scale-out网络与DCN网络融合
其次,内存语义的实现将推动Scale-up与Scale-out的统一。Scale-up与Scale-out网络的本质差异正在消弭,二者都围绕“内存远程读取”这一核心需求展开演进。无论是NVLink的芯片间共享内存,还是RoCE的远程直接内存访问(RDMA),其目标都是消除GPU间的内存墙,实现数据的高效流动。这种技术趋同为两者的融合奠定基础。在协议层面,不论是UEC、ESUN或是UALink,底层纷纷采用以太网进行承载,利用以太网领先的带宽能力和广泛生态,可以快速构建新标准下的生态系统。因此无论是对内存拷贝的共同需求还是以太网的统一生态,都将推动Scale-up和Scale-out网络走向进一步的融合。
这种融合不仅解决了当前AI训练的通信瓶颈,更为未来异构计算、存算一体等新型架构提供了网络基础。当数据中心网络真正实现“算力即服务”的愿景时,DCN、Scale-out与Scale-up的界限将彻底消弭,取而代之的是一个统一的、智能的、可演进的算力互联生态。
对基础架构/基础设施的影响
(DCI网络)
Agentic AI技术快速崛起的背景下,人工智能应用场景不断扩展(如自动驾驶、智能搜索与应答、智能推荐、医疗诊断、情绪分析、教育等),Agentic AI针对多归属(不同机构/公司的AI平台及资源)和多地域(不同地区/国家/省市等的AI平台及资源)推理和训练资源的调用和访问将会逐渐成为常态,而业界普遍采用的ScaleUP和ScaleOut的解决方案无法覆盖Agentic AI的多元跨域资源调用,利用多域多归联合计算的方式突破大规模Agentic AI计算和通信的归属和地理限制成为重点,亟需在归属/空间/电力/资源/算法/数据安全等方面进行协同和优化,使得分散的AI算力资源和存储资源从管理逻辑和计算效果上趋同于集中化的集群效果,业内为此创造了新的名词:跨区域扩展架构(Scale-Across)。
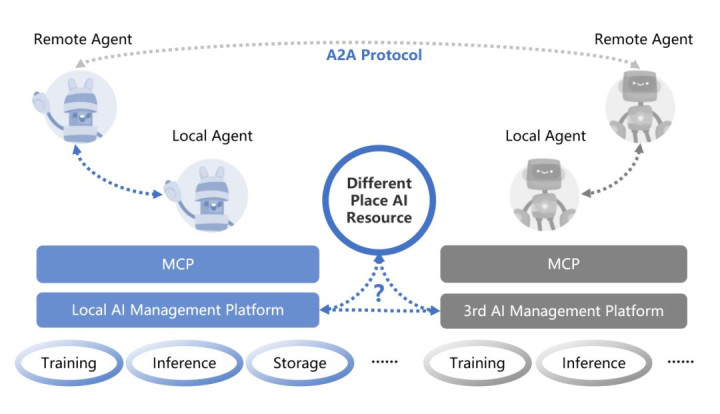
跨区域扩展架构(Scale-Across)下,分散的AI算存集群必然面临跨IDC机房混合训练和推理,对于IDC机房间通信网络的带宽/延迟以及可靠性等方面提出更高要求,业界在方案/算法/管理架构等方面对此有诸多思路弥补这种鸿沟。例如:
英伟达推出Spectrum-XGS以太网技术,通过距离自适应拥塞控制、精准延迟管理、端到端遥测三大算法创新与特定硬件组合协同优化,解决了跨地域GPU集群的通信延迟、拥塞与同步难题。
H3C则提出了“端侧优化+网关增强+广网升级”一体化方案、跨数据中心RDMA解决方案等:
“端侧优化+网关增强+广网升级”一体化方案借助RDMA加速网关在集成了数据包缓存、ACK代答、拥塞通告与选择性重传四大功能,在SRv6流量调度能力加持下,实现超长距有效带宽提升6倍。
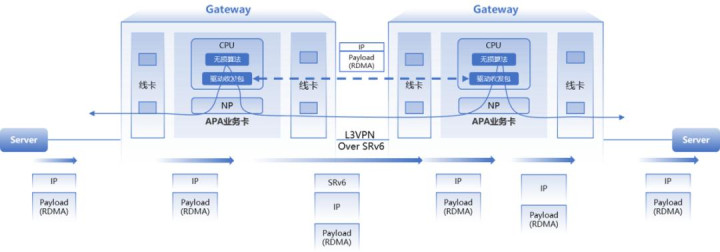
跨数据中心RDMA解决方案,通过数据中心出口S12500R-2XL/S12500R-128DH交换设备部署RDMA业务,分别验证了50KM和100KM两个场景,PP&DP拉远在50KM/100KM拉远距离下整体训练/推理性能损失可忽略,解决了单个机房训练电力资源短缺以及数据安全等问题,证明了跨数据中心拉远训练/推理技术方案的可行性,并在Top互联网客户成功部署上线。
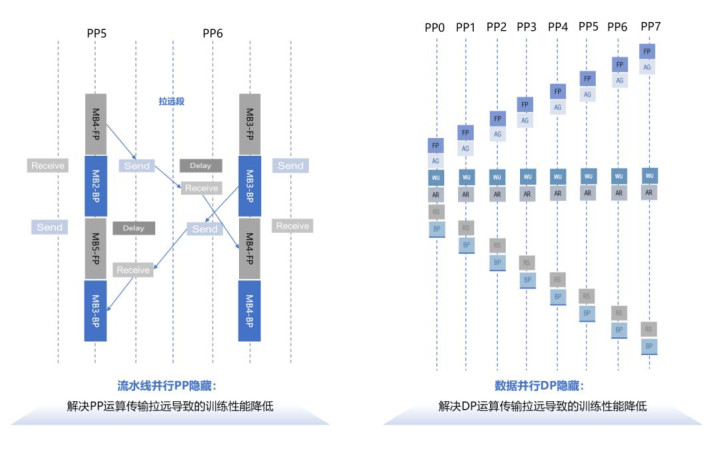
此外,在跨域训练/推理场景下除了从网络层面加速外,也可以从训练/推理的流水线并行和数据并行方面入手,流水线并行以及数据并行的流量特征与广域网的高延迟、有限带宽特性可在一定程度上适配,可将PP过程和DP过程合理分布于不同域,采用PP隐藏技术和DP隐藏技术进行优化,有效利用广域网的异属异构资源,降低全局开销,为Agentic AI模型训练和推理提供更灵活更深度的分布式扩展路径。
诚然,从网络层面以及训推/推理业务层面进行优化,可以很好的提高Agentic AI场景跨广域训练/推理业务效率,但是无法发挥异属异构的训练推理资源的协同作用,难以将整体资源利用率最大化,极容易造成数据中心各种智算资源的浪费。由此可见,将异属异构的算力及存储等资源统筹,形成统一的数据中心智算资源网络进行灵活编排和调度成为关键,算力资源的池化接入和管理以及智算跨域调度平台显得异常重要。
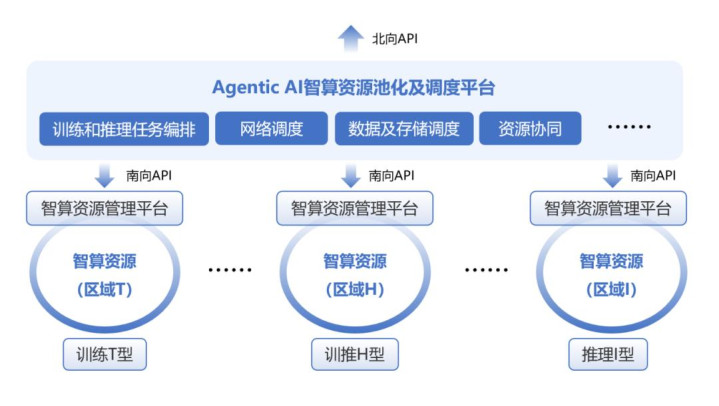
笔者认为,此调度平台需要同时具有北向API和南向API,北向API实现用户的统一接入/认证和管理,南向API实现地域以及算力架构差异屏蔽,实现异属异构的算力资源和网络资源统一接入和管理,通过平台支撑大模型作业任务的跨域调度和计费等,实现算力资源训练和推理的异地同步/异属合并/异构混合,配合Agentic AI提供方形成统一的运营平台,满足算力资源从构建到部署、运营的全链路技术支持需要,真正实现无界算力。
总结
随着Agentic AI业务的持续发酵,我们谈AI算力,不再谈TFlops、PFlops,而是谈GW、10GW、100GW;我们谈AI基础设施单元,不再谈OAM机型、超节点,而是谈AI集群、AI工厂。我们相信Agentic AI将对现有业务范式带来一场深层次全方位的变革,有幸身处这场变革其中,新华三也将不遗余力助力各位同仁乘势而上、共谱华章!
巨港配资,股票配资知识网,萧山股票配资提示:文章来自网络,不代表本站观点。



